Object Detection
I am interested in multi-class object detection, in particular, into representations that scale sub-linearly with the number of classes and detection schemes that efficiently explore the space of possible object hypotheses.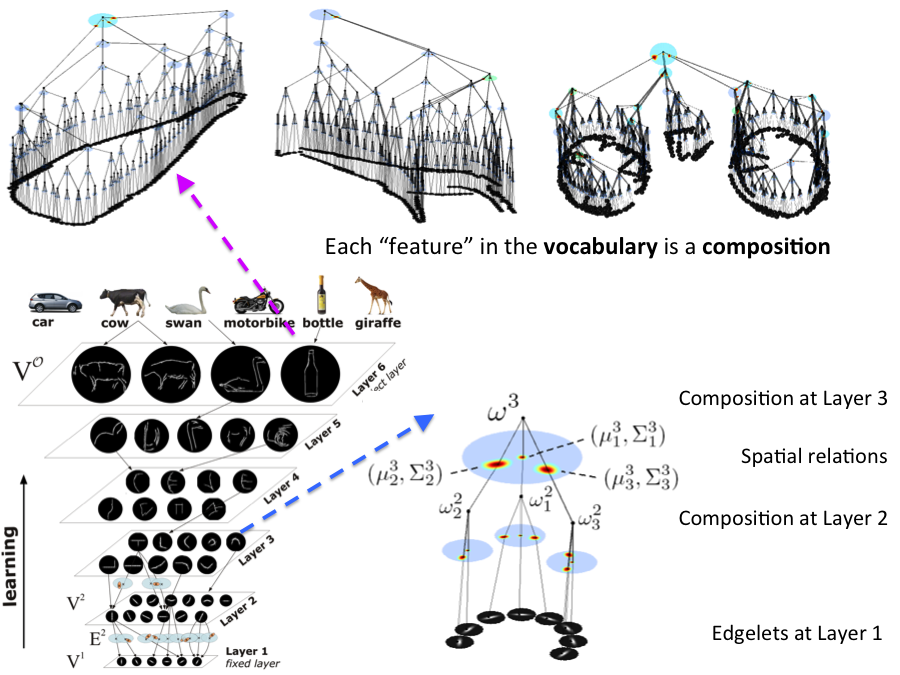
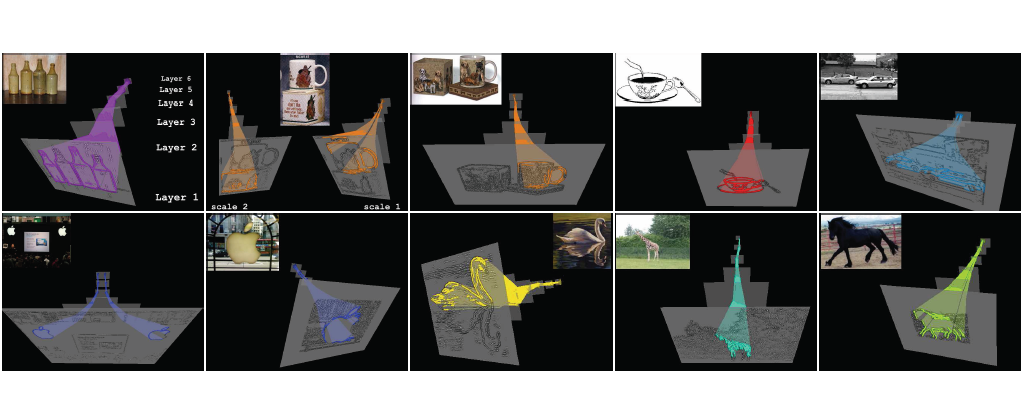
Compositional, Multi-class Object Detection
Hierarchies allow feature sharing between objects at multiple levels
of representation, can code exponential variability in a
compact way and enable fast inference. This makes them potentially
suitable for learning and recognizing a higher number of object
classes.
We developed a novel framework
for learning a hierarchical compositional shape vocabulary
for representing multiple object classes. The approach takes simple
contour fragments and learns their frequent spatial configurations.
These are recursively combined into increasingly more complex and class-specific shape compositions. The lower layers are learned jointly on
images of all classes, whereas the higher layers of the vocabulary
are learned incrementally, by presenting the algorithm with one
object class after another. The experimental results show that the
learned multi-class object representation scales favorably with the
number of object classes.
Relevant Publications
Towards Scalable Representations of Object Categories: Learning a Hierarchy of Parts
In Conference on Computer Vision and Pattern Recognition (CVPR), 2007
Similarity-based cross-layered hierarchical representation for object categorization
In Conference on Computer Vision and Pattern Recognition (CVPR), 2008
Evaluating multi-class learning strategies in a generative hierarchical framework for object detection
In Neural Information Processing Systems (NIPS), 2009
A coarse-to-fine Taxonomy of Constellations for Fast Multi-class Object Detection
In European Conference in Computer Vision (ECCV), 2010
A Probabilistic Model for Recursive Factorized Image Features
In Conference on Computer Vision and Pattern Recognition (CVPR), 2011
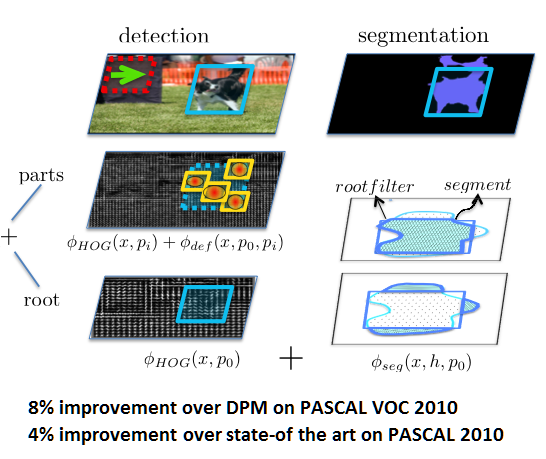
Exploting Segmentation in Detection
We are interested in how semantic segmentation can help object detection. We propose a novel deformable part-based model which exploits segmentation algorithms that compute candidate object regions. Our approach allows every detection hypothesis to select a segment, and scores each box in the image using both the traditional HOG filters as well as a set of novel segmentation features. Thus our model ``blends'' between the detector and segmentation models. Our approach significantly outperforms DPM and existing state-of-the-art approaches on the challenging PASCAL VOC 2010 dataset.
Relevant Publications
Bottom-up Segmentation for Top-down Detection
In Conference on Computer Vision and Pattern Recognition (CVPR), Portland, USA, June 2013 [project page]
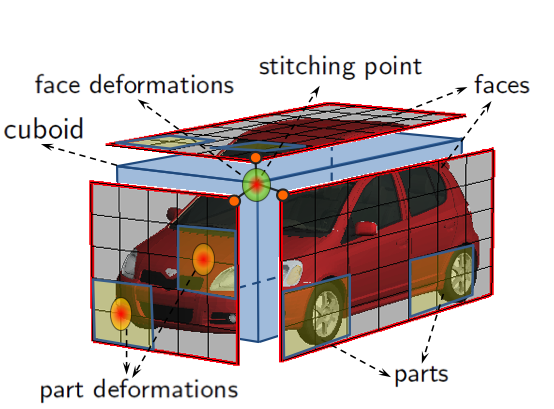

3d Object Detection from Monocular and RGB-D Imagery
We are interested in the problem of category-level 3D object detection. Given an image, our aim is to localize the objects in 3D by enclosing them with tight oriented 3D bounding boxes. For monocular images we extend the deformable part-based model to reason in 3D. We represent an object class as a deformable 3D cuboid composed of faces and parts, which are both allowed to deform with respect to their anchors on the 3D box. Inference then entails sliding and rotating the box in 3D and scoring object hypotheses. While for inference we discretize the search space, the variables are continuous in our model. For RGB-D data we propose a CRF model that reasons jointly about the class of each cuboid, scene type, and object-object, object-scene interdependencies.
Relevant Publications
3D Object Detection and Viewpoint Estimation with a Deformable 3D Cuboid Model
In Neural Information Processing Systems (NIPS), Lake Tahoe, USA, December 2012
[CAD dataset]
Holistic Scene Understanding for 3D Object Detection with RGBD cameras
In International Conference on Computer Vision (ICCV), Sydney, Australia, December 2013
Holistic Scene Understanding from RGB and RGB-D Imagery
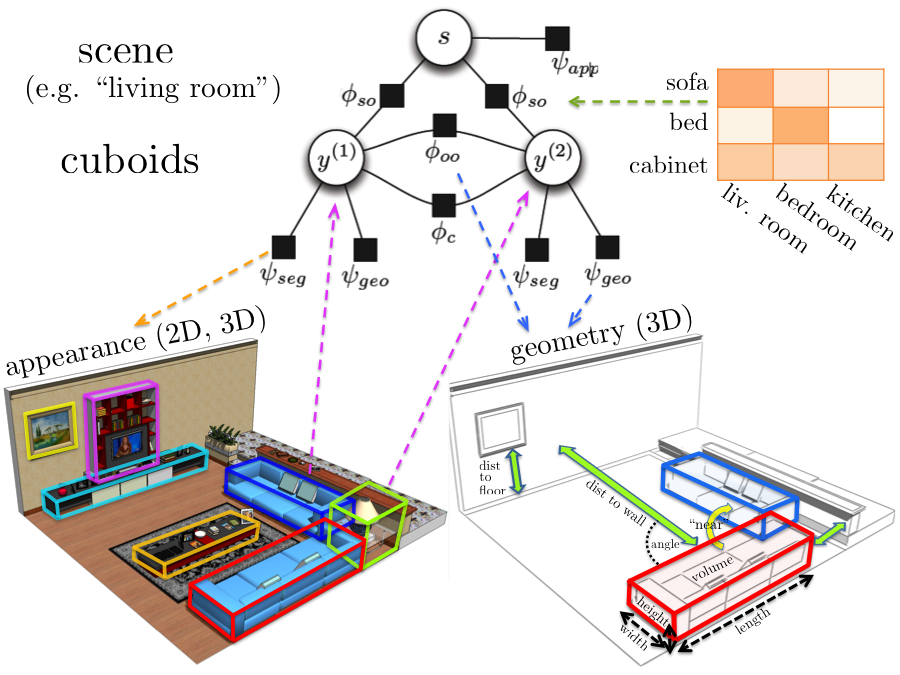
We developed several approaches to holistic scene understanding from RGB and RGB-D imagery that reason jointly about multiple related tasks such as segmentation, detection, annotation and scene classification. We represent the problem with a Conditional Random Field with carefully designed potentials. We show that the joint model improves performance in all tasks. Furthermore, our model achieves state-of-the-art in segmentation on the MSRC dataset while being an order of magnitude faster. For detection, our model significanly improves over DPM.
Relevant Publications
Holistic Scene Understanding for 3D Object Detection with RGBD cameras
To appear at International Conference on Computer Vision (ICCV), Sydney, Australia, December 2013
Describing the Scene as a Whole: Joint Object Detection, Scene Classification and Semantic Segmentation
In Conference on Computer Vision and Pattern Recognition (CVPR), Providence, USA, June 2012
[project page]
A Sentence is Worth a Thousand Pixels
In Conference on Computer Vision and Pattern Recognition (CVPR), Portland, USA, June 2013
Analyzing Semantic Segmentation Using Human-Machine Hybrid CRFs
In Conference on Computer Vision and Pattern Recognition (CVPR), Portland, USA, June 2013
Generating and Exploting Sentential Descriptions for Scene Understanding
In robotics, language is the most convenient way to teach an autonomous agent novel concepts or to communicate the mistakes it is making. For example, when providing a novel task to a robot, such as "pass me the stapler", we could provide additional information, e.g., "it is next to the beer bottle on the table". This information could be used to greatly simplify the parsing task. Conversely, it also crucial that the agent communicates its understanding of the scene to the human, e.g., "I can't, I am watching tv on a sofa, next to the wine bottle."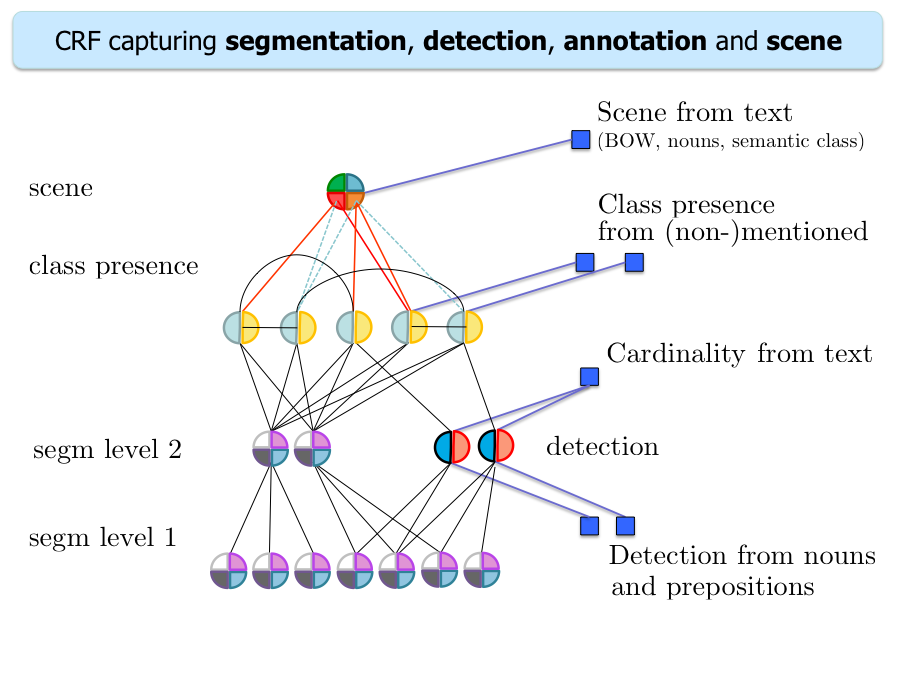
We propose a holistic CRF model for semantic parsing that employs text as well as image information as input.
We automatically parse the sentences and extract objects and their relationships, and incorporate them into the model,
both via potentials as well as by re-ranking candidate detections. We significantly improve over the visual only
model.
For text generation, we developed a system that produces sentential
descriptions of video: who did what to whom,
and where and how they did it.
Relevant Publications
A Sentence is Worth a Thousand Pixels
In Conference on Computer Vision and Pattern Recognition (CVPR), Portland, USA, June 2013
Video In Sentences Out
In Conference on Uncertainty in Artificial Intelligence (UAI), 2012
[project page]
Unsupervised Disambiguation of Image Captions
In First Joint Conference on Lexical and Computational Semantics (*SEM), 2012